수업/머신러닝
[머신러닝] 1일차 - 머신러닝 개요
분홍야자
2023. 4. 12. 09:45
학습목표
- 머신러닝의 개념 이해
- 머신러닝의 종류 및 과정
- 기계학습과 관련된 기본 용어
머신러닝 (Machine Learning)이란?
.
기계학습 - 컴퓨터를 학습시키는 것
인공지능(Artificial Intelligence)의 한 분야
프로그래밍 된 컴퓨터
컴퓨터가 데이터를 분석하고 학습하여
스스로 패턴을 찾고 예측하는 능력을
갖추도록 하는 기술
.
크게 3가지로 분류 됨
지도학습(Supervised Learning)
비지도학습(Unsupervised Learning)
강화학습(Reinforcement Learning)
.
바둑의 경우의 수는
첫 수부터 모든 수까지 약 2 x 10^170 개
머신러닝의 출현

엘런 튜링의
" 1950년도에 기계가 인간과 같은 사고를 할 수 있는가? "
가 화두가 되었다.
머신러닝의 발전
컴퓨터가 공부할 자료는 데이터이다.
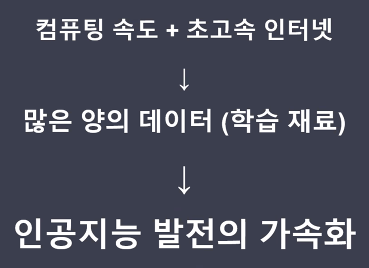

산업혁명
- 18세기 영국에서부터 시작되었음
- 획기적으로 바뀌게 되는 계기
산업혁명의 흐름
- 1차 기계
- 2차 전기
- 3차 컴퓨터
- 4차 AI, IoT, BigData
인공지능 (Artificial Intelligence)
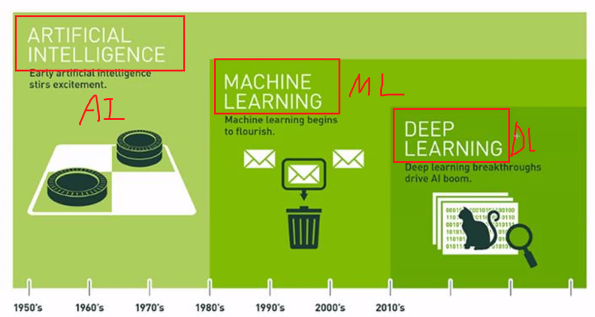
머신러닝
- 사람을 흉내내는 모든 분야
- 정확한 규칙을 세워서 처리하는 일
- 세상에는 모든 일에 규칙을 세울 수가 없다. -> 머신러닝 탄생
- 사람을 흉내내는 걸 학습시킨다.
- 데이터를 기반으로 학습을 시켜서 예측하게 만드는 기법
- 인공지능의 한 분야로 컴퓨터가 학습 할 수 있도록 하는 알고리즘과 기술을 개발하는 분야
- 학습을 통해
- 데이터를 이용하여 특성과 패턴을 학습하고 그 결과를 바탕으로 미지의 데이터에
- 통계학, 데이터마이닝, 컴퓨터 과학이 어우러진 분야
- 데이터 마이닝 : 대규모 데이터에서 유용한 정보를 추출하는 프로세스
- 자연어 처리

딥러닝
- 매번 똑같지 않게 생겼지만 같은 사람을 구분하고 분류하는것
- 고양이인지 개인지 구분하는 것
- 추상적인 걸 학습시켜 사람처럼 판별이 가능하게 하는 것
Rule-based expert system



- 단점
- 스팸 메일 필터가 안된다..
- 매번 같은 표정, 옷 일 수가 없기에 얼굴 인식 시스템 개발 불가
- 많은 상황에 대한 규칙들을 모두 만들어 낼 수 없다.
머신러닝

- 머신러닝이란 학습을 통해 새로운 데이터를 예측하거나 분류하는 것
데이터를 이용하여 특성과 패턴을 학습 -> 미래 결과를 예측 (판단, 추론)
의료 인공지능 분야 사례
- 영상 의료/병리 데이터의 분석 및 판독 (Deep Learning) - 영상의학과 전문의

산업 인공지능 분야 사례
- 신제품 마케팅 - 인공지능 트렌드 분석 시스템 '엘시아(LCIA)'

예술 인공지능 분야 사례

머신러닝 종류
지도학습 (Supervised Learning)
- 이게 문제이고, 이게 답이야 라고 알려줌
- 데이터에 대한 라벨 (명시적인 답) 이 주어진 상태에서 컴퓨터를 학습시키는 방법
- 규칙을 찾아감
- 분류와 회귀로 나뉘어진다. - 분류와 회귀로 나눠지는 것에 문제는 중요하지 않다. 답이 중요하다.
- 분류 (Classification)
- 미리 정의된 여러 클래스 레이블 중 하나를 예측
- 속성(Attribute)값을 입력, 클래스 값을 출력하는 모델 -> 모델에 문제를 입력하고 답을 출력 시키는 모델
- 붓꽃(iris)의 세 품종 중 하나로 분류, 암 분류 등.
- 예측값이 다르면 타격이 크다
- 이진분류, 다중 분류 등이 있다
- 이진분류 (Binary Classification) : 둘 중 하나
- 다중분류 (Multi-class Classification) : 여러 개 중 하나
- 회귀 (Regression)
- 연속적인 숫자를 예측
- 속성 값을 입력, 연속적인 실수 값을 출력하는 모델
- 어떤 사람의 교육 수준, 나이, 주거지를 바탕으로 연간 소득 예측.
- 예측 값의 미묘한 차이가 크게 중요하지 않다. -> 조금 달라도 별 차이가 없다.
- 분류 (Classification)
- 지도, 비지도, 강화중에서 가장 중점이 된다.
- 예시
- 스팸메일 분류 - 분류
- 집 가격 예측 - 회귀 (연속적인 수치를 예측)
class = lable = 답
feature = attribute = column = 문제
비지도학습 (Unsupervised Learning)
- 지도학습이 아니다.
- 데이터에 대한 정답이 없는 상태에서 컴퓨터를 학습
- 학습시키려는데 문제는 있으나 답이 명시적이지 않다.
- 데이터의 숨겨진 특징, 구조, 패턴을 파악하는데 사용
- 데이터를 비슷한 특성끼리 묶는 클러스터링 (Clustering)과 차원 축소 (Dimensionality Reduction)등이 있다.
- 클러스터링 : 데이터 내에서 유사한 패턴이나 구조를 찾아 그룹화하는 것을 목적
- 차원 축소 : 고차원의 데이터를 저차원으로 축소시키는 기법
강화학습(Reinforcement Learning)
- 지도학습과 비슷하지만 완전한 답(Label)을 제공하지 않는 특징이 있음
- 특정한 환경(Environment) 내에서 행동(Action)을 하고, 그에 대한 보상(Reward)을 받아 보상을 최대화하는 방향으로 학습을 진행하는 것
- 기계는 더 많은 보상을 얻을 수 있는 방향으로 행동을 학습
- 주로 게임이나 로봇을 학습시키는데 많이 사용
머신러닝이 유용한 분야
- 기존 솔루션으로는 수동 조정과 규칙이 필요한 문제
- 전통적인 방식으로는 전혀 해결 방법이 없는 복잡한 문제
- 새로운 데이터에 적응해야하는 유동적인 환경
- 대량의 데이터에서 통찰을 얻어야 하는 문제
머신러닝 과정

- 문제 정의 (Problem Identification)
- 비즈니스 목적 정의
- 모델을 어떻게 사용해 이익을 얻을까?
- 현재 솔루션의 구성 파악
- 지도 vs 비니도 vs 강화
- 분류 vs 회귀
- 비즈니스 목적 정의
- 데이터 수집 (Data Collect)
- File (csv, xml, json)
- Database
- Web Crawler (뉴스, sns, 블로그)
- IoT 센서를 통한 수집
- Survey
- 데이터 전처리 (Data Preprocession)
- 결측치, 이상치 처리
- 특성공학 (Feature Engineering)
- 단위변환 (Scaling)
- 새로운 속성 추출 (Transform)
- 범주형 -> 수치형 (Encoding)
- 수치형 -> 범주형 (Binning)
- 탐색적 데이터 분석 (EDA, Exploratory Data Analysis) - 시각화 그래프
- 기술통계 (의미가 있는 값), 변수간 상관 관계
- 시각화
- pandas
- matplotlib
- seaborn
- Feature Selection (사용할 특성 선택) - 학습이 잘될 수 있는 특성 선택
- 모델 선택, Hyper Parameter 조정
- Hyper Parameter : 모델의 성능을 개선하기 위해 사람이 직접 넣는 parameter
- 목적에 맞는 적절한 모델 선택
- KNN, SVM, Linear Regression, Ridge, Lasso, Decision Tree, Random forest, CNN, RNN ...
- 학습 (Model Training)
- model.fit(X_train,y_train) - 파라미터 값으로 문제와, 답을 학습시킨다.
- train 데이터와 test 데이터를 7 : 3 정도로 나눔
- model.predict(X_test) - 테스트를 하는데 문제만 주고 답을 내게 한다.
- 데이터의 70% 는 train 데이터, 30% 는 test 데이터로 사용
- 70% 로 학습시키고 실사용 전에 학습이 잘 되었는지 30%로 테스트 한다.
- model.fit(X_train,y_train) - 파라미터 값으로 문제와, 답을 학습시킨다.
- 평가 (Evaluation)
- 정확도 (accuracy)
- 실제 중 얼마나 맞췄는가
- 예측 중 얼마나 맞췄는가
- 정확도의 오류
- 재현율 (recall)
- 정밀도 (precision)
- 스팸메일의 경우 내가 원하는 메일이였는데 스팸메일로 구분 되어
- f1 score
- 정확도 (accuracy)

