수업/머신러닝
[머신러닝] 4일차 - for문 사용하여 하이퍼 파라미터 튜닝, 결정 트리 (Decision tree)
분홍야자
2023. 4. 19. 09:45
수업정리
- 학습이 끝난 모델링의 상태
- 일반화 : train 상 test 상
- 과대적합 : train 상 test 하
- 훈련 데이터에만 과도하게 정확히 동작
- 과소적합 : train 하 test 하
- test 데이터 셋 은 미래데이터의 역할을 한다
- 성능은 테스트셋의 스코어로 알수있다.
- 새로운 데이터 포인트 - 예측 데이터
- 가장 가까운 훈련 데이터셋의 데이터 - 훈련된 데이터
- 분류 - 다수결 : classification
- 회귀 - 평균 : regression
- k값 소 -> 모델의 복잡도가 증가
- k값 대 -> 모델의 복잡도가 감소

- train_test_split
- x,x,y,y 순으로 담아준다. train, test 순
- 75:25 비율로 담아줌
- train_test_split : 랜덤 샘플링
수업시작
하이퍼 파라미터 튜닝 (for문 사용)

# 비어있는 리스트 만들어주기
train_list = []
test_list = []
for k in range(1,105,2):
# 이웃의 변화에 따른 모델 생성
model = KNeighborsClassifier(n_neighbors=k)
model.fit(X_train, y_train)
train_score = model.score(X_train, y_train) # 정확도
train_list.append(train_score)
test_score = model.score(X_test, y_test)
test_list.append(test_score)- metrics = 평가에 관련된 모듈이 담겨있음
그래프 그리기
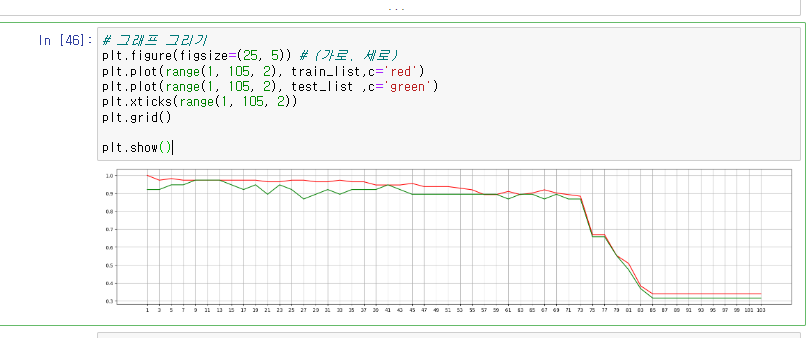
# 그래프 그리기
plt.figure(figsize=(25, 5)) # (가로, 세로)
plt.plot(range(1, 105, 2), train_list,c='red')
plt.plot(range(1, 105, 2), test_list ,c='green')
plt.xticks(range(1, 105, 2))
plt.grid()
plt.show()- 어떤 k값을 이용하는게 좋을까
최적화된 모델 활용

final_model = KNeighborsClassifier(n_neighbors=9)
final_model.fit(X_train, y_train)final_model.score(X_test, y_test)
예측해보기 - predict

my_dict = final_model.predict([[3.7,4,2.0,0.4]])
my_dict예측한 붓꽃 이름 확인해보기

# 붓꽃 종류 확인하기
iris_data['target_names'][my_dict]
학습목표
- Decision Tree 알고리즘 이해
- Label 인코딩과 One-hot인코딩 이해
- 교차 검증 기법 이해
결정 트리 (Decision tree)
- 의사결정
- Tree를 만들기 위해 예/아니오 질문을 반복하며 학습
- 다양한 앙상블(ensemble) 모델이 존재
- RandomForest, GradientBoosting, XGBoost, LightGBM
- 분류와 회귀에 모두 사용 가능

- 결정 트리가 뒤집어 놓으면 나무같다 하여 tree 라고 지칭하였다.
- 시작부분은 root node
- 끝부분은 leaf node
- 한명의 타깃값이 있는 node를 순수 노드라고한다
- tree 의 질문을 통해서 타겟값을 결정한다.
- 업다운 게임처럼 1~100이라고 가정했을 때 처음에 외치는 값이 50인 이유는 절반을 날려버리기 위해
- 절반의 타겟을 날리는 질문을 한다.

- 불순도가 낮은 방향으로 가야 한다.
- 질문을 던지고 규칙을 찾는다
- 모든 노드가 순수 노드가 될 때까지 학습하면 복잡해지고 과대적합이 됨
- 새로운 데이터 포인트가 들어오면 해당하는 노드를 찾아 분류라면 더 많은 클래스를 선택하고, 회귀라면 평균을 구함
- 장점
- 학습과정을 확인 가능하다
- 질문을 볼 수 있음
- 어떤 규칙을 통해 학습 되었는지 알 수 있음
- 단점
- 트리가 깊어지면 과대적합이 되기 쉬움

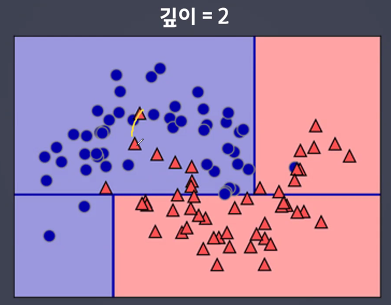

- 깊이가 깊어질 수록
- 깊이를 선택한다.
- 불순도를 계산을 디시션 트리가 한다.
장단점 및 주요 매개변수
- 트리의 최대 깊이 : max_depth
- 리프 노드의 최대 개수 : max_leaf_nodes
거리 기반 숫자스케일링
특성중요도 : 어떤 특성이 타겟값에 얼마만큼의 영향을 끼치는지
- 디시션 트리는 거리가 아닌 질문이다.
- 특성 중요도를 통해 질문을 뽑는다.
- 정규화나 표준화가 필요 없다.
- 훈련데이터 범위 밖의 포인트는 예측 할 수 없다.
- 미래 시간에 대한 질문은 예측이 어렵다
- 가지치기를 사용함에도 불구, 과대적합되는 경향이 있다.
- 일반화 성능이 좋지 않다.
머쉬룸 데이터셋 사용하기

import pandas as pd
import numpy as np
import matplotlib.pyplot as plt# 데이터 가져오기
data = pd.read_csv('mushroom.csv')
data
결측치 확인

# 결측치 여부 확인 - 없당!
data.info()
# 데이터셋 나누기
X = data.loc[:,'cap-shape':] # data.drop('poisonous',axis=1) : poisonous 버리고
y = data.poisonous
라벨 인코딩
- 컴퓨터가 이해할 수 있는 언어로 된 데이터를 줘야 학습하고 규칙을 찾는다.
- 숫자 -> 인코딩
- 단순 수치 값으로 mapping 하는 작업

이때 발생하는 문제
- 수에는 크기가 있다. 대와 소...
- 숫자로 표기해주었을 뿐인데 숫자 크기의 대소 관계로 인해 일반화된 학습이 아닌 학습이 잘 안될 수 있다.
- 그래서 One-hot Encoding 을 해준다
- 0 과 1의 값을 가진 여러개의 새로운 특성으로 변경하는 작업
- 학습종류가 3개일 경우 3개의 컬럼을 만든다.
- 해당 컬럼별로 값이 맞으면 1, 아니면 0

One-hot Encoding
- 범주형 변수를 표현하는데 가장 널리 쓰이는 방법
- 분류하고자 하는 범주(종류)만큼의 자릿수(컬럼)를 만들고 단 한 개의 1과 나머지 0으로 채워서 숫자로 표현하는 방식
- 정답 라벨이 아닌 문제 라벨을 인코딩하는 작업
- 컴퓨터는 숫자 데이터밖에 이해를 못하기 때문에 인코딩 필요
- 특성 컬럼의 라벨 범주 갯수만큼 컬럼을 만든다
원핫 인코딩 처리 - pd.get_dummies(X)

X_one_hot = pd.get_dummies(X)
X_one_hot
모델링 나누기

from sklearn.model_selection import train_test_split# 훈련, 테스트 데이터 나누기
# test_size - test셋의 비율 조정
X_train, X_test, y_train, y_test = train_test_split(X_one_hot, y, test_size = 0.3)
결정트리 모델 사용하기

from sklearn.tree import DecisionTreeClassifiertree_model = DecisionTreeClassifier() # 하나의 모델객체 생성

# 트리 모델 학습
tree_model.fit(X_train, y_train)tree_model.score(X_train,y_train)- 결과가 너무 잘되어도 의심해보자..
- 이렇게 잘 나온 이유는 뭐지?