수업정리

- GAN : 예측 추론을 떠나서 생성해버림 -> 논란이 많이 생김
- Generative Adversarial Networks의 약자로 우리말로는 “적대적 생성 신경망”
- 서로 다른 두 개의 네트워크를 적대적으로(adversarial) 학습시키며 실제 데이터와 비슷한 데이터를 생성(generative)해내는 모델
- 비지도 학습 기반 생성모델로 분류
- epochs
- 학습 횟수
- 학습 : 최적화
- 머신러닝은 사람의 개입이 들어감
- 딥러닝은 사람의 개입이 거의 안들어감
- 알아서 해준다고 딥러닝만 사용한다는 건 적합하지 않는다
- 상황에 따라 머신러닝 모델을 선택할 지 딥러닝 모델을 선택할지 성능을 더 잘 낼 모델을 찾아야함
- 딥러닝
- 컴퓨터비젼, 음성,
- 복잡하고 많은데이터에 유용
수업시작
딥러닝 실습 (신경망 모델)

모델 만들기
# 신경망 구조 설계
model = Sequential() # 딥러닝 모델을 구성하는 뼈대, 층을 쌓을 수 있게 도와줌
# input_shape(한행의 데이터의 컬럼 수,
model.add( InputLayer(input_shape=(1,)) ) # 입력층
# Dense 인공신경 망, 마지막은 1로 맞춰줘야 한다.
model.add(Dense(units=9)) # 신경 세포 망
model.add(Dense(units=9))
model.add(Dense(units=1)) # 출력층
데이터가 들어오는 곳
데이터의 크기 알려줘야함
다중,이진분류인지, 회귀 인지에 따라 마지막 뉴런의 units 수가 달라진다.
회귀 일때 units = 1
학습방법 및 평가 방법 설정
# 2. 신경망 모델 학습(loss, optimizer)/평가(metrics)방법 설정
model.compile( loss='mean_squared_error',
optimizer='SGD')
학습 및 학습과정 시각화와 히스토리에 담아주기
# 3-1. 학습 및 학습과정 시각화 / 히스토리 생성
studentHistory = model.fit(X_train, y_train, epochs=100) # epochs : 최적회 학습 횟수
히스토리를 시각화

모델평가

# 4. 모델 평가
model.evaluate(X_test,y_test)test 결과와의 loss 값 차이가 많이 벌어졌다 -> 과적합 된 듯 하다.
퍼셉트론 개념
- 딥러닝의 근간
- 이진 분류를 수행하는 데 사용
- 입력과 가중치를 곱한 값들의 합이 임계값(threshold)을 초과하는 경우, 출력으로 1을 반환하고, 그렇지 않은 경우에는 0을 반환
- 인공 신경망의 초창기 모델 중 하나
- 단층 퍼셉트론과 다층 퍼셉트론으로 나뉘어짐
- 단층 퍼셉트론은 선형 분리 가능한 문제에 대해서만 작동
- 다층 퍼셉트론은 여러 개의 은닉층을 포함하며, 비선형적인 패턴을 인식하는 데 사용
역치
- 어떤 값이나 수준을 기준
- 이진 분류(Binary Classification)에서 사용되는 중요한 개념 중 하나
- 어떤 입력값이 주어졌을 때 그 값이 역치보다 크면 1을, 작으면 0을 반환하는 함수를 만드는 데 사용
- 분류의 성능에 매우 중요한 역할
- 모델의 정확도를 향상시키는 데 큰 영향을 미

- 자극이 역치 이상이 되어야 다음뉴런에게 전달이 되는 개념

- 자극값을 다음 뉴런에게 넘길 지 말지 판단하는 활성화 함수 가 추가됨 (activation)

- 활성화 함수로 시그모이드 사용한 예시

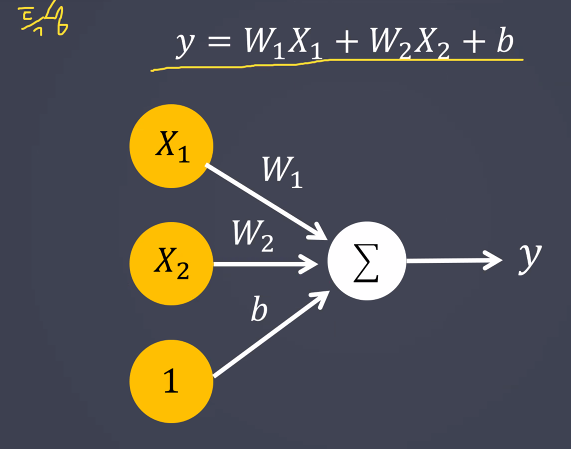

- 예측값이 활성화 함수를 만나야 다음 신경망으로 전달이 된다.
- 예측값은 다음 뉴런층의 데이터값이 된다.

선형함수 모델과 활성화 함수까지 만나야 하나의 퍼셉트론이다.
선형함수 + 활성화함수 = 퍼셉트론
계단함수

- 계단함수이다.
- 맨 처음 도입된 함수이지만 별로 좋지 않아서 지금은 쓰지 않는다

- 영향력은 W 에 의함
XOR 이라는 문제가 생긴다.

둘다 True 여야 1이 나온다.

하나라도 1이면 1

둘다 같은 값이면 0
둘의 값이 달라야 1
이 문제점을 해결한 게 다층 퍼셉트론




유방암 데이터셋 분류 ( 이진분류 )


모델링

- activation='sigmoid'
- activation : 활성화 함수는 인공 신경망의 출력 값을 조정하는 함수
- 'sigmoid' 함수는 입력 값을 0과 1 사이의 값으로 제한하는 함수
- 이진분류 문제에서 자주 사용
- 'validation_split = 0.2'
- 전체 학습 데이터를 학습용 데이터와 검증용 데이터로 나누는 비율을 8:2로 설정
- Adam
- RMSProp와 Momentum을 결합한 알고리즘으로, 지수 가중 이동 평균과 모멘텀을 이용하여 가중치를 업데이트
오차 확인
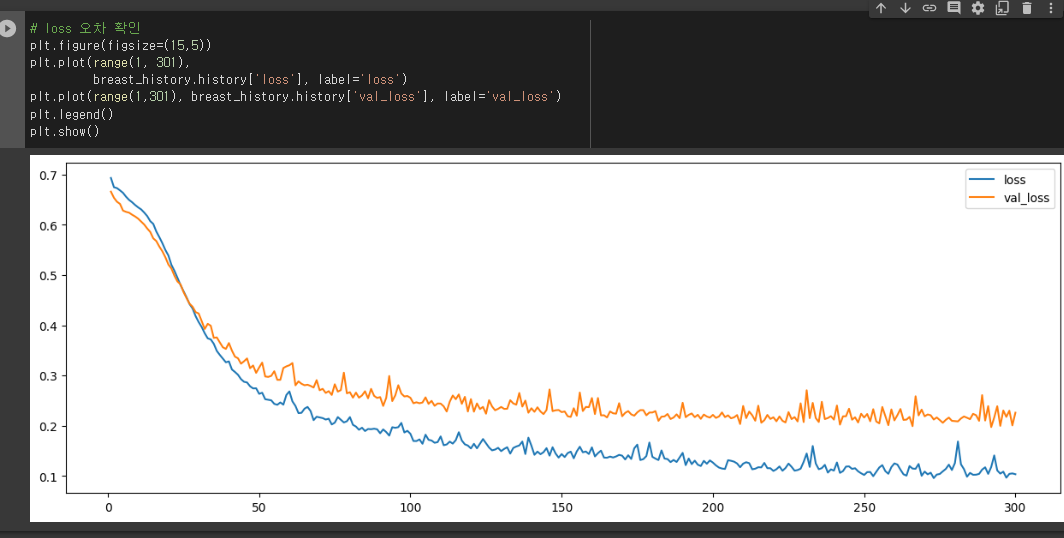
정확도 확인

'수업 > 딥러닝' 카테고리의 다른 글
| [딥러닝] 7일차 - 이미지 데이터 학습, 데이터 확장 (0) | 2023.05.17 |
|---|---|
| [딥러닝] 6일차 - cnn (0) | 2023.05.15 |
| [딥러닝] 4일차 - (0) | 2023.05.10 |
| [딥러닝] 3일차 - 다중분류 실습 (0) | 2023.05.09 |
| [딥러닝] 1일차 (0) | 2023.05.02 |