수업정리
분류 (Classification) - 미리 정의된 여러 클래스 레이블 중 하나를 예측하는 것
머신러닝 진행과정
1. 주제정하기, 목적선정
2. 데이터 수집
3. 데이터 전처리
4. 기술통계, 데이터간 상관 관계 파악
5. 모델 선택과 하이퍼 파라미터 조정
6. 모델 훈련
7. 성능 확인, 시험, 평가
수업시작
학습목표
학습된 모델의 상태를 표현하는 단어 3가지
- 일반화
- 모델을 훈련시키는 목적, 정확히 예측시키도록 잘 만들어진 모델상태
- 성능이 훈련, 시험 모두 잘 나오는 것
- train 성능 95%, test 93%
- 과대적합
- 훈련 세트에 너무 맞추어져 있어 테스트 세트의 성능 저하
- 조금이라도 달라지는 문제에 대해 정답을 내지 못함
- 공부는 100점 시험은 0점
- 훈련 데이터에만 과도하게 정확히 동작
- ex) 둥글고, 5각형의 무늬가 있고, 반짝반짝 광이나면 공이다.
- 성능이 훈련만 잘나오고, 시험은 잘 안나오는 것
- train 성능 90%, test 90%


- 과소적합
- 훈련 세트를 충분히 반영하지 못한 훈련 세트, 테스트 세트에서 모두 성능이 저하
- 너무나도 단순
- 둥글면 다 공이다
- 성능이 모두 훈련, 시험 모두 잘 안나오는 것
- train 성능 60%, test 55%

모델 복잡도 곡선
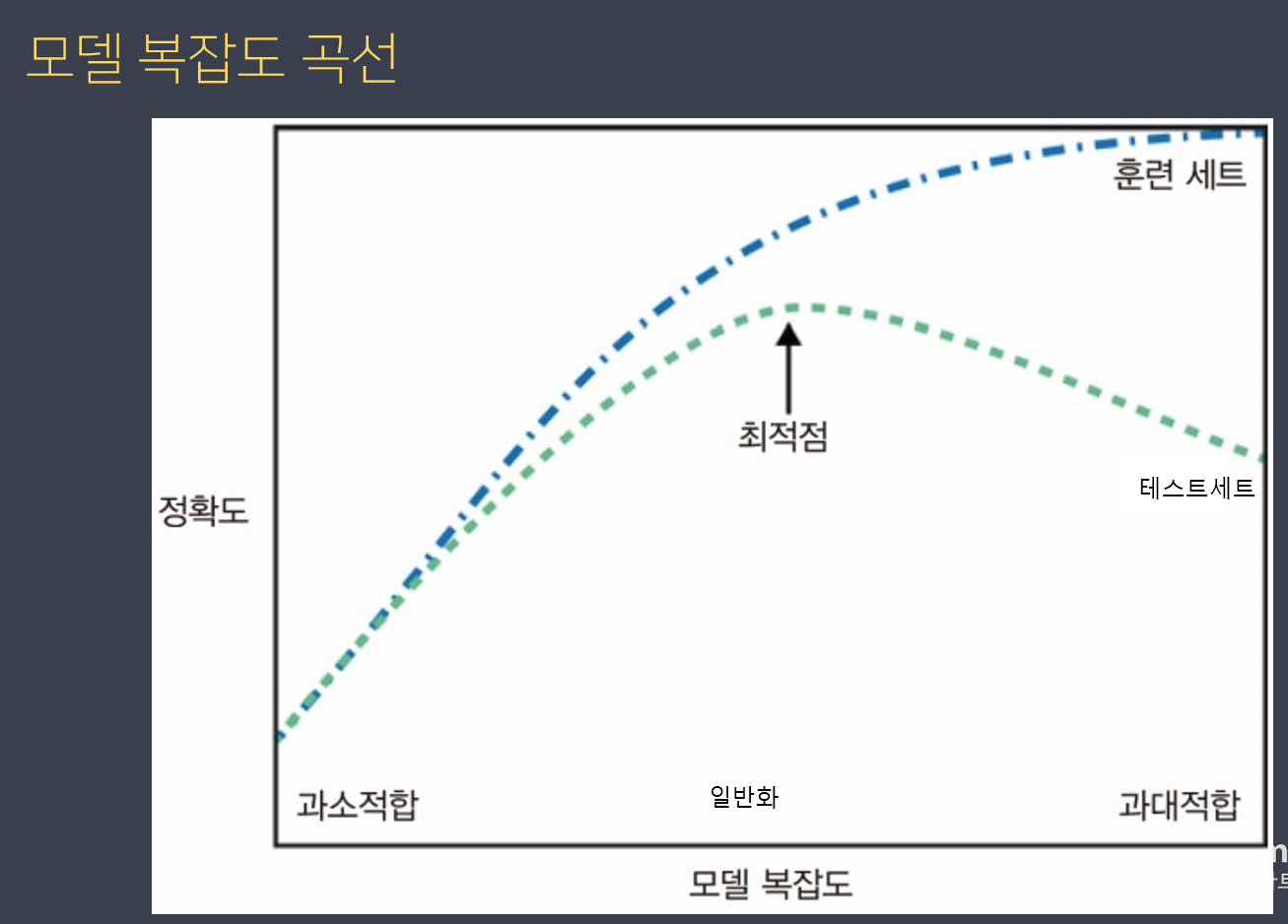
파란 점선은 훈련 데이터, 초록 점선은 테스트 데이터
왼쪽에서 오른쪽으로 갈 수록 복잡하다 -> 앞부분은 단순하다. / 뒷부분은 복잡하다. (규칙을 너무 많이 쌓였다)
과대적합
- 규칙을 찾는게 아닌 문제를 외워버리는 상태
훈련 세트는 훈련 할 수록 성능이 올라가나,
테스트 세트는 미래에 예측할 데이터로 생각하면됨.
테스트데이터의 성능이 가장 높은 지점인 것이 일반화된 모델이라고 볼수있다.
세트 = 데이터
해결 방법
- 질 좋은 데이터로 학습, 많은 양의 데이터로 학습
- 훈련 데이터의 다양성 보장
- 암인 사람 50. 암아닌 사람 50 이렇게 골고루 데이터를 가져와야 한다
- 다양한 데이터의 포인트를 골고루 나타내야함
- 편중된 데이터는 버리기
- 규제 (Regularization) 를 통해 모델의 복잡도를 적정선으로 설정
암인지 아닌지, 판단하는 모델을 만들 때
암인 사람 50. 암아닌 사람 50 이렇게 골고루 데이터를 가져와야 한다
딥러닝은 학습하는 횟수를 정한다.
문제는 과대적합이다.
특히 딥러닝 가면 데이터가 복잡
딥러닝은 영상이나 이미지
모델의 구조도 사람이 직접 설계
사이킷런을 사용하여 몇줄안되는 코드로 쉽게 훈련 시킬수가 있음
딥러닝은 밀키트 같은거다.
라이브러리를 제공
쉽게할 수있도록 재료를 주면 내가 조립을 해야한다.
모델 학습의 상태 - 일반화, 과대적합, 과소적합
KNN (K - Nearest Neighbors)
k-최근접 이웃 알고리즘
- 가장 가까운 데이터를 찾는다.
- k는 갯수
- k값에 따라 가까운 이웃의 수가 결정됨
- 분류와 회귀에 모두 사용가능하다
- 새로운 데이터 포인트와 가장 가까운 훈련 데이터 셋의 데이터 포인트를 찾아 예측
- k 는 하이퍼 파라미터
- k 값이 작을 수록 모델의 복잡도가 상태적으로 증가
- 반대로 k값이 커질수록 모델의 복잡도가 낮아짐
- 100개의 데이터를 학습하고 k를 100개로 설정하여 예측하면 빈도가 가장 많은 클래스 레이블로 분류
- 데이터에 민감하게 반응한다.


장단점 및 주요 매개변수 (하이퍼파라미터)
사이킷런에서 하이퍼파라미터 사용방법

- 이해하기 매우 쉬운 모델
- 훈련 데이터 세트가 크면 (특성, 샘플의 수) 예측이 느려진다
- 데이터가 클수록 예측이 느려진다.
- 수백 개 이상의 많은 특성을 가진 데이터 세트와 특성 값 대부분이 0인 희소(sparse)한 데이터 세트에는 잘 동작하지 않는다.
- 성능이 좋지않다.
- 거리계산을 할 때 잘 동작 안함 000000000050000000005000
- 예측할 때 작동한다.
- 데이터가 클수록 예측이 느려진다.
- 거리를 측정하기 때문에 같은 스케일(scale)을 같도록 정규화 필요
- 사람은 범위만 봐도 키를 뜻하는지 시력을 뜻하는지 몸무게를 뜻하는지 알지만 컴퓨터는 아니다.

붓꽃(iris) 데이터셋

- 클래스 3가지로 이루어져있다.
- 클래스가 0은 setosa, 1은 virginica, 2는 versicolor 이다. 그러므로 이 클래스 데이터의 종류는 분류데이터이다
실습해보기
기본적으로 사용할 라이브러리 import하기

import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris



iris_data = load_iris() # 사이킷런 데이터셋 중 붓꽃 데이터셋 가져와서 변수에 담기
# 데이터 확인
iris_data
# 데이터셋의 키값
iris_data.keys()
# 데이터셋의 데이터
iris_data.data
# 데이터 셋의 속성 명
iris_data.feature_names
# 데이터 셋의 레이블 값(정답), (꽃의 품종 정보)
iris_data.target
# 레이블 이름
iris_data.target_names
# 데이터 설명
print(iris_data.DESCR){ , , , } : 집합 자료형
{ key : value } : 딕셔너리 = 번치
- 150개의 데이터가 있다. ( 3개 클래스이며 각 클래스마다 50개의 데이터 존재)
- 4개의 속성이 존재
- sepal length - 꽃받침 길이
- sepal width - 꽃받침 너비
- petal length - 꽃잎 길이
- petal width - 꽃잎 너비
- 3개의 클래스 (라벨) 이 존재
- Setosa
- Versicolour
- Virginica
- Null값은 없다 (=결측치가 없다)
- 실습용, 공부용이기 때문에 잘 만들어진 데이터셋이다.
- 영국 통계학자 로널드 피셔 (Ronald Fisher)가 1936년에 발표한 논문 에서 사용된 데이터 셋이다.
- 기부자는 Michael Marshall 이다 (1988 년도에 데이터셋 기부)
데이터셋 pandas의 데이터프레임으로 만들기

# 데이터는 아이리스 데이터셋의 data, 컬럼은 아이리스 데이터셋의 feature_names
iris_df = pd.DataFrame(data = iris_data.data, columns=iris_data.feature_names)
탐색적 분석 (EDA)

pd.plotting.scatter_matrix(iris_df,figsize=(15,15),marker='o', c= iris_data.target,alpha=0.7)
plt.show()- 꽃 종류 별로 특징들이 세분화 되어있어서 학습이 잘 될 듯하다.
- 3개의 클래스가 꽃잎과 꽃받침의 측정값에 따라 비교적 잘 구분되는 것을 알 수 있다.

위 사진 같은 부분이 적절히 찾는게 모델의 성능을 좌우한다.
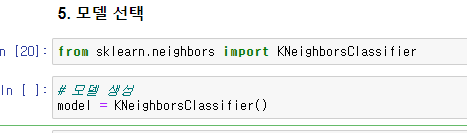
from sklearn.neighbors import KNeighborsClassifier
# 모델 생성
model = KNeighborsClassifier()
사이킷 런 라이브러리 안에 모델을 편리하게 나눠줄 수 있는 기능이 존재한다

from sklearn.model_selection import train_test_split# train_test_split (문제, 정답)
X_train, X_test, y_train, y_test = train_test_split(iris_data.data, iris_data.target)순서 중요 ,xxyy 순서
random_state : 랜덤을 고정시킨다
랜덤이 정말 랜덤일까

classification_report 라이브러리는 분류 결과 보고서이다
모델이 복잡해질 수록 학습데이터는 정확도가 높아지지만
테스트 데이터는 너무 복잡해지면 성능이 좋아지지 않는다.
예측 데이터를 잘 맞출 수 있는 일반화 지점을 잘 찾아야 한다
분류는 다수결 (적절한 이웃의 수를 찾아야 한다 = KNN )
회귀는 평균값
KNN 은 예측할 때 실제 작용한다
'수업 > 머신러닝' 카테고리의 다른 글
| [머신러닝] 6일차 - (ㅎㅎㄷ쌤) 선형모델 (0) | 2023.04.21 |
|---|---|
| [머신러닝] 5일차 (0) | 2023.04.20 |
| [머신러닝] 4일차 - for문 사용하여 하이퍼 파라미터 튜닝, 결정 트리 (Decision tree) (0) | 2023.04.19 |
| [머신러닝] 2일차 - 수업 정리와 scikit-learn 을 활용하여 지도학습 시켜보기 (0) | 2023.04.13 |
| [머신러닝] 1일차 - 머신러닝 개요 (0) | 2023.04.12 |