수업정리
ex03_DecisionTree 활용 버섯 데이터 분류_230419_수.ipynb
0.41MB
- 디시젼 트리 (Decision Tree)
- 트리를 만들기 위해 스무고개 하듯이, 예 / 아니오 질문을 반복하며 학습
- 어떤 질문을 하는지가 가장 중요
- 단점을 장점으로 승화 한게 앙상블
- 분류와 회귀에 모두 사용
- 시작 노드는 root node
- 끝 노드는 leaf node
- 질문에 따라 불순도가 다르기에 불순도가 최대한 낮아지는 질문을 해야 함
- 순도가 높다는 건 불순도가 낮고, 순도가 낮으면 불순도가 높다.
- 목적은 불순도가 낮게
- 타깃값 이 하나인 것 순수 노드
- 모든 노드가 순수 노드가 될 때까지 학습하면 복잡해지고 과대적합이 된다. -> 복잡한 모델이 됨
- 회귀는 평균을 내서 값을 낸다.
- 지니불순도 알고리즘 사용
- 단점
- 범위 밖의 포인트는 예측 할 수 없다
- 가지치기를 함에도 불구하고 과대적합이 되는 경향이 있어 일반화 성능이 좋지 않음
- 과대적합이 되기 쉽다
- 사전 가지치기 (pre-pruning)와 사후 가지치기 (pruning)
- 사이킷런은 사전 가지치기만 지원한다
- 장점
- 모델을 시각화 할 수 있어 이해가 쉬움
- 특성이 개별 처리되기 때문에 데이터 스케일에 영향을 받지 않아 정규화나 표준화가 필요 없음
- 특성의 중요도를 계산하기 때문에 특성 선택에 활용가능 ()
- 매개변수
- 트리의 최대 깊이 : max_depth
- 리프 노드의 최대 개수 : max_leaf_nodes
- 리프 노드가 되기 위한 최소 샘플의 개수 : min_samples_leaf
- Label Encoding - 단순 수치값으로 mapping 하는 작업
- 컴퓨터가 인식할 수 있는 숫자 데이터로 변환
- 단점
- 순서가 아닌 단순히 라벨링인 숫자일 뿐인데 수치의 대소로 인하여 올바른 학습이 되지 않을 수 있다
- One-hot Encoding - 0 과 1의 값을 가진 여러 개의 새로운 특성으로 변경하는 작업


수업 시작
학습목표
- 독 / 식용 두가지로 분류 : 이진분류
- 과대적합 속성제어 : 가지치기
- 특성중요도

기존 23개의 컬럼 -> 117개로 늘어남
graphviz (그래프 비즈) 패키지 이용하여 시각화
환경변수란?
필요한 것을 가져오라고 명령했는데 어디에있는지 모르기 때문에
경로를 지정해주는 것
지금까지는 아나콘다 개발환경을 사용했기에 환경변수를
https://graphviz.gitlab.io/_pages/Download/Download_windows.html
https://graphviz.org/download/
graphviz.gitlab.io

클릭하여 설치하고
실행 하면

마침나올때까지 그냥 다음만 클릭

설치확인

시스템 환경변수 편집 열기

환경변수 클릭

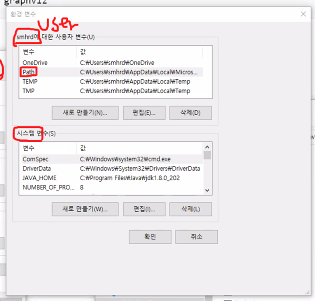
path 클릭

새로만들기 클릭

bin 경로 복사

추가하고 확인 클릭

path 더블클릭해서 편집키 켜기

새로만들기 눌러서

C:\Program Files\Graphviz\bin\dot.exe 추가
확인 클릭하고 나와서 또 확인 클릭
인스톨 해주기

!pip install graphviz

from sklearn.tree import export_graphviz
import graphviz
기존 모델 객체 - 깊이설정안한 상태


# 파일 만들기
export_graphviz(tree_model, out_file = 'tree.dot',
class_names=['독','식용'],
feature_names=X_one_hot.columns,
impurity=False,
filled=True)
# out_file : 저장할 파일의 이름실행해주면

생성된걸 확인 가능
결정트리 시각화
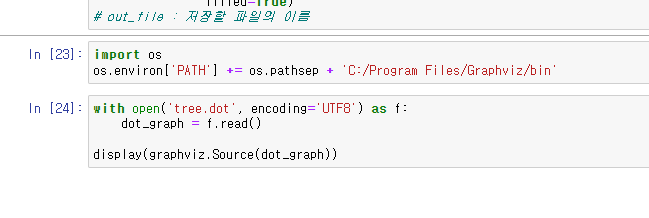
import os
os.environ['PATH'] += os.pathsep + 'C:/Program Files/Graphviz/bin'with open('tree.dot', encoding='UTF8') as f:
dot_graph = f.read()
display(graphviz.Source(dot_graph))
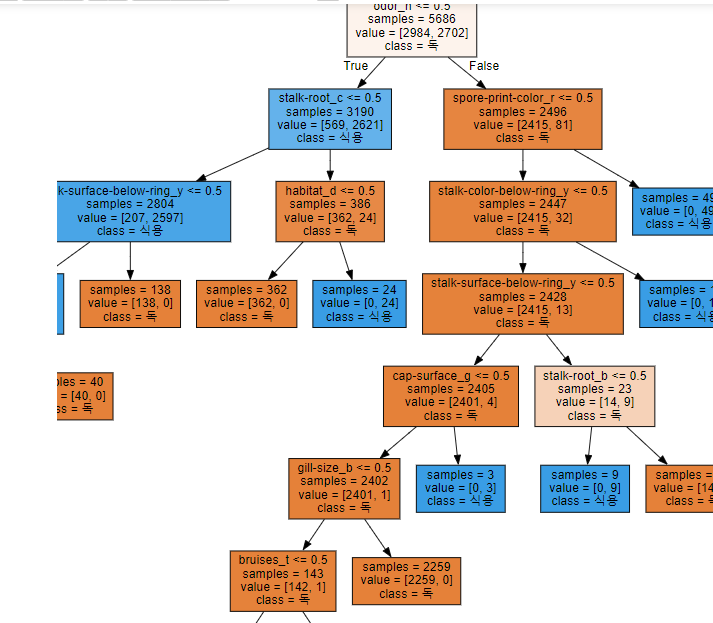
색이 진할 수록 불순도가 낮다.
보는 방법


- 첫번째 줄은 질문, 두번째 줄부터는 노드의 상태이다.
- odor_n <= 0.5odor_n
- odor : 냄새종류 중 n
- 해석 = odor_n 가 0이냐 1이냐
- samples = 5686
- 해석 train 데이터셋 개수 - 5686개
- value = [2984,2702]
- class = value 수가 많은 것의 y 값
- 왼쪽 true 오른쪽 false
- 가장 불순도가 낮을 질문을 계속 던짐
- 질문이 없는 것은 샘플 수와 한쪽만 값이있는 value 값이 동일하기에 leaf 노드가 된상태이다
과대적합이라 생각했을 때 제어하기
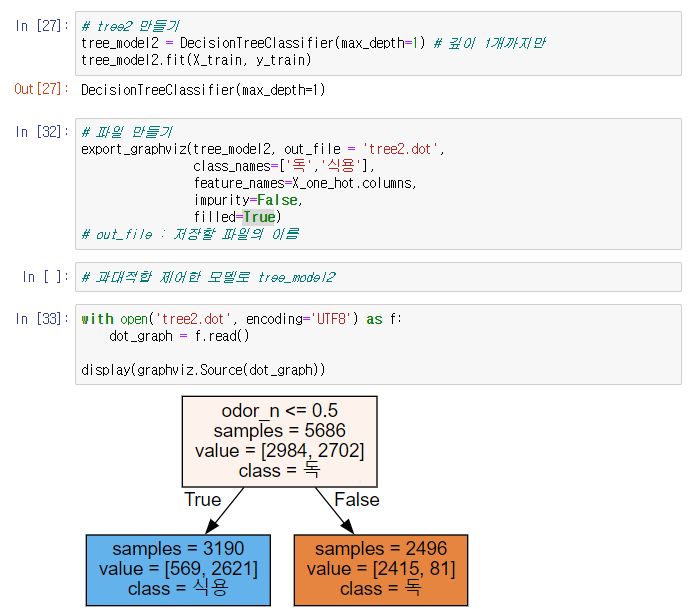
max_depth 값 설정
# tree2 만들기
tree_model2 = DecisionTreeClassifier(max_depth=1) # 깊이 1개까지만
tree_model2.fit(X_train, y_train)
# 파일 만들기
export_graphviz(tree_model2, out_file = 'tree2.dot',
class_names=['독','식용'],
feature_names=X_one_hot.columns,
impurity=False,
filled=True)
# out_file : 저장할 파일의 이름
with open('tree2.dot', encoding='UTF8') as f:
dot_graph = f.read()
display(graphviz.Source(dot_graph))
교차검증 (Cross validation)
모델의 성능이 좋게 나올 때까지 하이퍼파라미터를 튜닝한다.
일반화 성능이 나올 때까지 튜닝
기존 학습
- 문제
- 테스트 세트에 맞게 학습 될 수 있다. - 테스트 데이터에 과대적합
- 해결
- 기존 7:3으로 나눈 train과 test 비율을 train 에서 또 7:3으로 나눈다.
- Validation Data (검증) 을 나눈다.
- 문제
- 데이터가 줄어든다.
- 또 다시 검증 데이터에 과대적합

학습 평가 데이터 나누기를 여러번 반복하여 일반화 에러를 평가

- 데이터 셋을 k개로 나눈다.
K-fold cross-validation 동작 방법

- 모든 데이터가 한번도 겹치지 않고 테스트 셋으로 사용가능하다!
- 조금씩 다른 상태의 학습 데이터로 사용 가능하다
- 데이터가 다를 때 얼마나 민감하게 반응하는지 알 수 있다.
- 장점
- 데이터의 여러 부분을 학습하고 평가하여 일반화 성능을 측정하기에 안정적이고 정확함 (샘플링 차이 최소화)
- 모델이 훈련 데이터 민감도 파악 가능
- 데이터 세트가 많지 않아도 유용하게 사용가능
- 단점
- 여러 번 학습하고 평가하는 과정을 거치기에 계산량이 많아진다 (비용이 많음)

from sklearn.model_selection import cross_val_score# 다섯번 교차검증하여 성능 확인
tree_result = cross_val_score(tree_model, X_train, y_train, cv=5)
tree_result# 교차검증 성능: 각 세트의 평가결과의 평균을 구한다
tree_result.mean()- 교차검증성능은 각 세트별 평가 결과의 평균이다.
특성 중요도
순위에 상관없이 단순한 특성 중요도

# 학습된 트리모델의 특성 중요도
fi = tree_model.feature_importances_
fi보기편하게 DataFrame으로 만들고 이후에 정렬 하고 상위 10개만 보기

odor_n 이 제일 중요도가 제일 높다는 걸 알 수 있음
# 모델의 특성 중요도와 특성의 이름을 이용해 dataframe 생성
importance_df = pd.DataFrame(fi, index=X_one_hot.columns, columns=['name'])
# 생성된 df 값을 내림차순으로 정리
importance_df.sort_values(by='name',ascending=False)
'수업 > 머신러닝' 카테고리의 다른 글
| [머신러닝] 7일차 (0) | 2023.04.24 |
|---|---|
| [머신러닝] 6일차 - (ㅎㅎㄷ쌤) 선형모델 (0) | 2023.04.21 |
| [머신러닝] 4일차 - for문 사용하여 하이퍼 파라미터 튜닝, 결정 트리 (Decision tree) (0) | 2023.04.19 |
| [머신러닝] 3일차 - 모델의 상태 3가지, 붓꽃 데이터 셋 실습 (0) | 2023.04.14 |
| [머신러닝] 2일차 - 수업 정리와 scikit-learn 을 활용하여 지도학습 시켜보기 (0) | 2023.04.13 |