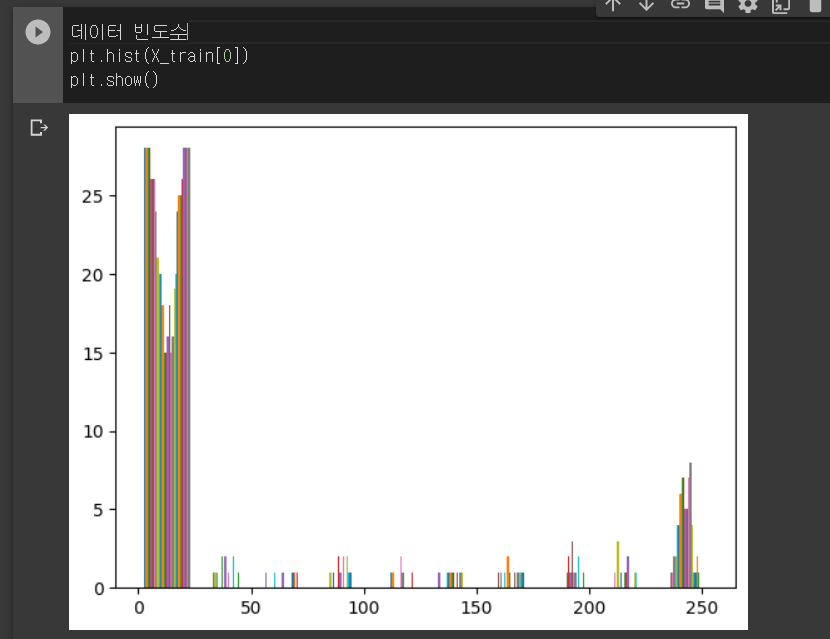
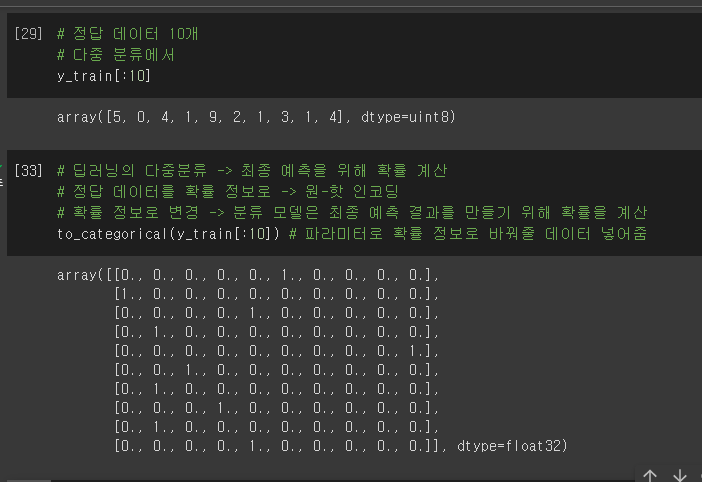
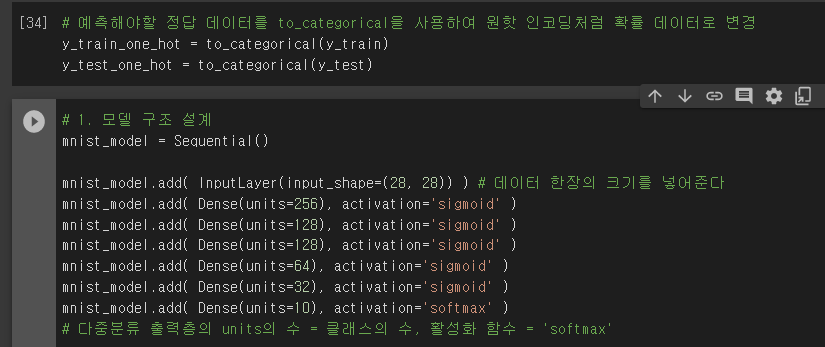
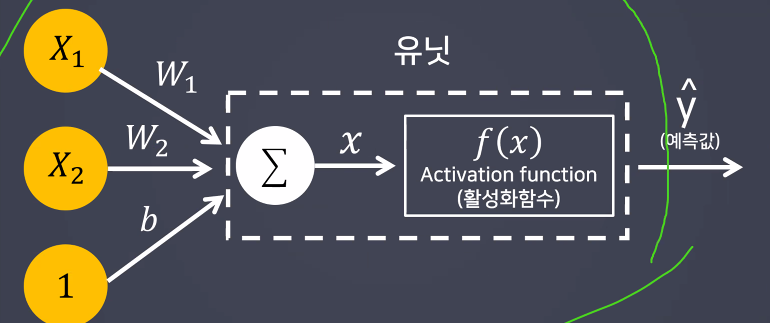
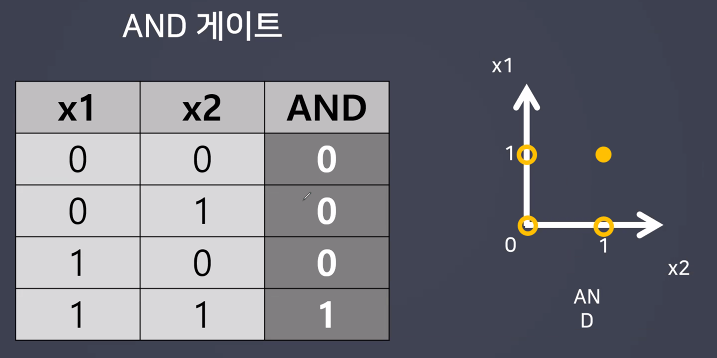
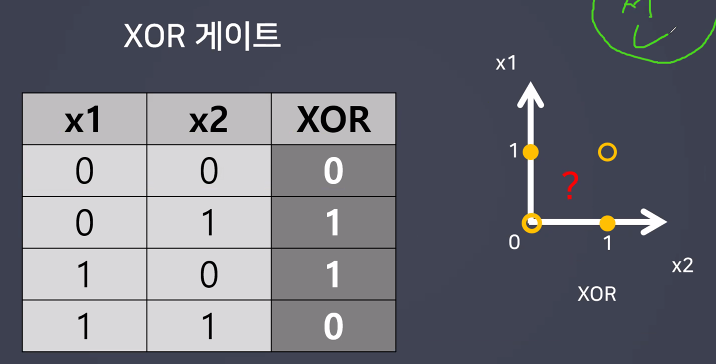
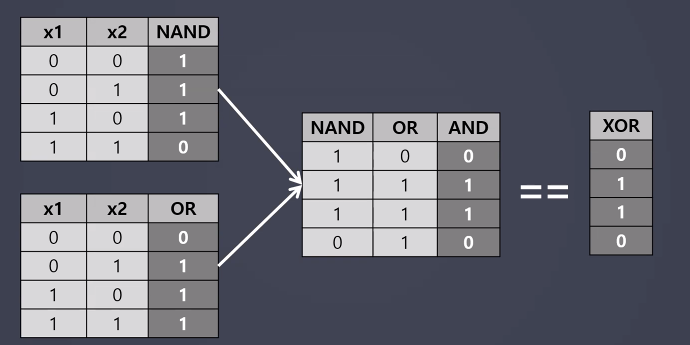
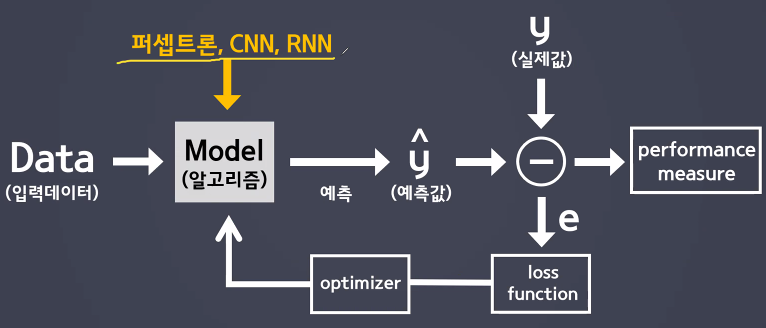
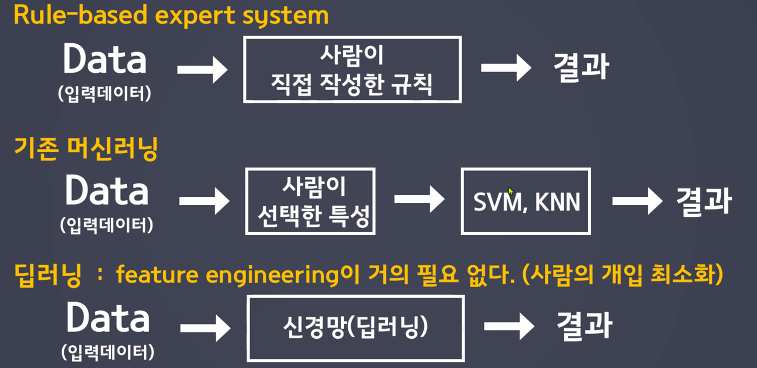
수업정리
- 다중분류
- 각각 클래스별로 확률을 내어 결과를 도출해 내는 것
- 확률정보로 학습시키기 위해서 원핫인코딩으로 만든다
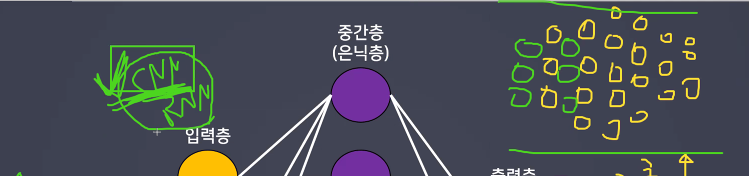
- Flatten
- 2차원을 고려하지 못함
- 2차원인 데이터들을 1차원으로 펴줘야 수식을 세우고 계산을 할 수 있다
- 가중치만큼 계산을 해내는 것 뿐이다
- 위치는 입력층 뒤에 은닉층 전에 쌓아준다.
- sigmoid
- sigmoid는 0과 1을 절대 벗어나지 않는 값만 도출해 낸다
- 이진분류나 회귀에서 사용됨
- softmax
- 모든 클래스의 확률을 구하고 그 모든 확률 값의 합이 1이 되게 만든다.
- categorical_crossentropy
- loss함수이다
- loss함수로 binary_crossentropy는 둘중 하나를 봄 -> 이진분류
- 다중분류시 사용
- 모든 클래스에 대해서 봐야하기 때문에 사용
수업시작
경사하강법
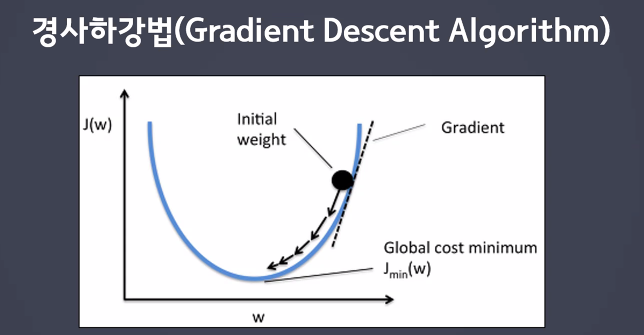
- 좋은 W를 찾고싶어서 나온 방법
- loss(손실)값이 낮은 모델을 찾는게 목적
- 어디에 가야할 지는 알았는데 어떻게 가야 좋을까?
- 가만히 있으면 해결이 되지 않는다
- 실패도 경험이다
- 기울기가 0인 지점을 찾자
- 가중치를 조금씩 바꿔가며 기울기가 낮아지는 방향으로 나아가는 것
- 지역 최적점에 빠진다.
- 글로벌 미니멈을 찾아야한다
- 중간지점에서 낮은 지점을 찾은 것을 로컬 미니멈이라고 한다.
확률적경사하강법

- 경사하강법
- 너무 오래걸리고 제대로 찾아가기가 어렵다
- 실제로 대입해봤을 때 성능이 별로 좋지가 않다.
- ex - 100개 중 100개
- 모든 과목을 전부다 공부
- 확률적경가하강법
- 랜덤하게 몇개만 선택을 해서 나아가자
- ex - 100개 중 30개
- 불안정 적이긴 하지만
- 과목중 골라골라서 효과적으로 공부
- 지역 최적점을 빠져나갈

모멘텀


- 관성이라는 개념을 도입
네스테로프 모멘텀

- 다음 스텝까지 고려해서 실제 t+1에 반영하여 업데이트
- t+ t+1
- 다 똑같은데 미분할 때 m
- 불필요한 이동울 줄이는 방법

아다그리드

- 학습률 감소 방법을 적용
- 어차피 머니까 학습률이 초반엔 커도 된다. 어차피 랜덤 값은 최적값과 멀테니까
- 0에 가까워지면서 학습률을 줄여나가며 0을 최대한 지나치지 않게 한다.
- 각각의 퍼셉트론마다 다르다.

경사, 학습률, 관성에 초점을 맞추는 방법들이 있다

- 모든 데이터검토하여 방향을 찾자
- 조금씩 데이터를 샘플로 검토하여 방향을 찾자
- 관성 개념을 도입해서 가자
- 다음스텝고려
- 학습률을 고려
- adadelta는 너무 작아지지는 않도록 방지해보자
- RMSProp는 상황을 보며 세밀해 지는정도를 정해보자 비율과 기울기를 고력
- Adam 경사와 학습률 둘다 고려

오차역전파

- 가중치(weight)와 편향(bias)의 값을 학습하기 위한 알고리즘
- 학습은 두가지로 나눠짐
- 순전파 : 전파가 원래방향대로 감
- 출력값을 찾아가는 과정 -> 추론
- 역전파 : 역으로 전파를 시킴
- 최적의 학습 결과를 찾아가는 것 -> 학습
- 순전파 : 전파가 원래방향대로 감
순정파

- 계산만 한 것
- 아무 w나 붙인 것
역전파
- 에러정보를 가지고 w들을 수정시킨다 그전에 있는 층이 수정이 됨
- w가 데이터를 이해하려고
- 출력층에서 입력층 쪽으로 전파
1epoch 는 순전 역전을 한 번씩 한 것
시그모이드 함수의 문제점


- 경사가 사라짐 -> 기울기 소실
- 계산할 기울기가 없다
- 기울기가 0이되어야 하는데 미분 사용
- 시그모이드를 통해서 0~1사이 값이 나오는데 미분시켰더니 아래 파란선이 나온다.
- 파란선 - 최대가 너무 낮음 0.25
기울기 소실
역전하면서 학습 할 때 기울기가 0이 되는 방향으로 가는데 찾는 방법은 미분을 해야한다
하다보니 미분을 할 수 있는 기울기 조차 사라져 버림
더이상 수정할 수가 없다
- 이를 해결하기 위해 다양한 역전파 방법들이 생김
다양한 역전파 방법

- tanh
- 하이퍼블릭 탄젠트 - 2배씩 늘려서 -1~1 로 잡음
- ReLU : 현재 많이 쓰고 우리도 사용한다
- 양수면 값을 살려두고 음수면 죽인다.
- Leaky ReLU
- 음수를 어느정도 조금 남겨 놓는 것
- Maxout
- 최대값을 살려놓는것
- GAN이라는 모델에 적합
- ELU
- Leaky ReLU를 좀더 완만하게 만든 것
- 학습량이 많고 연산이 복잡한 경향이 있다
새노트
회귀
- loss = MSE(평균제곱오차)
- 맨 마지막 (출력층) 뉴런 개수 : 1
- 활성화 함수 : linear(항등함수) / Default 임
이진분류
- loss = binary_crossentropy
- 맨 마지막 (출력층) 뉴런 개수 1
- 활성화 함수 : sigmoid
다중분류
- loss = categorical_crossentropy
- 맨 마지막 (출력층) 뉴런 개수 : 클래스 개수
- 활성화 함수 : softmax
fashion 데이터 분류

흑백화

다른방식으로 설계

모델 설계는 항아리 모양으로 하는게 좋다.

- 너무많은 퍼셉트론에서 갑자기 10개로 줄여버리면 뚝끊긴 느낌이니 잘 조절해 준다.
- 모델학습이 끝난
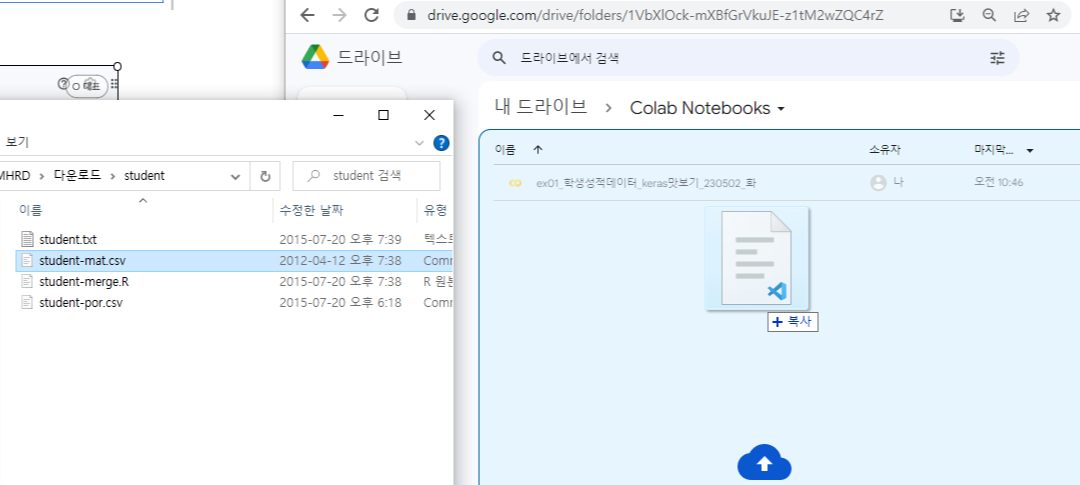
모델 저장
- 학습이 끝난 모델을 저장할 건데
- 경로부터 이동해준다

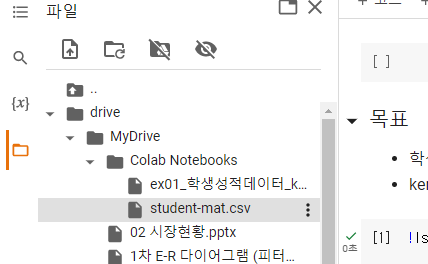
- 옮겨진 경로에 저장하기

- 구글 드라이브 연동 해서 들어가보면 저기 빨간박스 부분에 모델이 저장되어있을 것이다.

여기에 저장이 된다
모델 불러오기

'수업 > 딥러닝' 카테고리의 다른 글
| [딥러닝] 7일차 - 이미지 데이터 학습, 데이터 확장 (0) | 2023.05.17 |
|---|---|
| [딥러닝] 6일차 - cnn (0) | 2023.05.15 |
| [딥러닝] 3일차 - 다중분류 실습 (0) | 2023.05.09 |
| [딥러닝] 2일차 - 신경망 모델, 퍼셉트론, 다층퍼셉트론, 유방암데이터븐류 (이진분류) (0) | 2023.05.03 |
| [딥러닝] 1일차 (0) | 2023.05.02 |