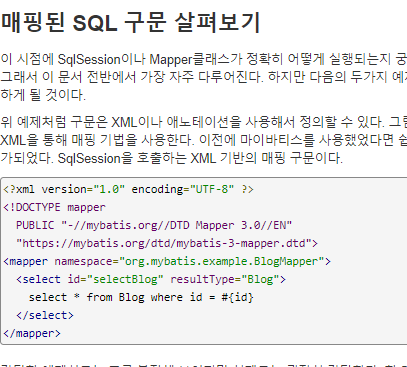
package com.smart.hrd.persistence;
import com.smart.hrd.domain.MemberDTO;
public interface IMemberDAO {
// 실체가 없는
// 강제성이 있다.
public String getTime();
public void insertMember(MemberDTO mDTO);
}
# 데이터 확인
iris_data
# 데이터셋의 키값
iris_data.keys()
# 데이터셋의 데이터
iris_data.data
# 데이터 셋의 속성 명
iris_data.feature_names
# 데이터 셋의 레이블 값(정답), (꽃의 품종 정보)
iris_data.target
# 레이블 이름
iris_data.target_names
# 데이터 설명
print(iris_data.DESCR)
{ , , , } : 집합 자료형 { key : value } : 딕셔너리 = 번치
150개의 데이터가 있다. ( 3개 클래스이며 각 클래스마다 50개의 데이터 존재)
4개의 속성이 존재
sepal length - 꽃받침 길이
sepal width- 꽃받침 너비
petal length - 꽃잎 길이
petal width- 꽃잎 너비
3개의 클래스 (라벨) 이 존재
Setosa
Versicolour
Virginica
Null값은 없다 (=결측치가 없다)
실습용, 공부용이기 때문에 잘 만들어진 데이터셋이다.
영국 통계학자 로널드 피셔 (Ronald Fisher)가 1936년에 발표한 논문 에서 사용된 데이터 셋이다.
@RequestMapping("/ex06")
public @ResponseBody SampleDTO ex06() { // @ResponseBody : 응답할 때 JSON 데이터로 반환
log.info("/ex06.................");
SampleDTO dto = new SampleDTO();
dto.setAge(10);
dto.setName("홍수영");
return dto;
}
실행결과
객체 자체를 @ResponseBody 어노테이션을 통해 알아서 JSON 화 시켜서 넘겨준다
Network 쪽에서 확인하기
Network > Preview 에서 json 데이터 확인 가능하다.
3. map 사용하기
@RequestMapping("/ex06_1")
public @ResponseBody Map<String, SampleDTO> ex06_1(){
log.info("/ex06_1.................");
SampleDTO dto = new SampleDTO();
dto.setAge(12);
dto.setName("홍길자");
Map<String, SampleDTO> map = new HashMap<String, SampleDTO>();
map.put("info", dto);
return map;
}
실행결과
4. 옛날에 json 썼던 방식
// 옛날에 만들던 json 방식
@RequestMapping("/ex07")
public ResponseEntity<String> ex07(){
log.info("/ex07............");
// 2010 년도에까지도...
// jQuery 가 활성화 되면서 json 데이터를 보내기 시작
// 스크립트는 규약에 따라서 데이터가 전송이 안되고 전송 받지도 못함.
// 크로스 도메인을 우회할 수 있다.
String msg = "{\"name\":\"홍길자\",\"age\":12}";
HttpHeaders header = new HttpHeaders();
header.add("Content-type", "application/json;charset=UTF-8");
// header와 똑같이 만들어줘야함
return new ResponseEntity<String>(msg, header, HttpStatus.OK);
}
json 방식을 직접 문자열로 써줘야 했고
header 객체를 사용하여 "Content-type" , "application/json;charset=UTF-8" 추가
// 파일 등록 화면 호출
@RequestMapping(value="/exFileUpload", method = RequestMethod.GET)
public void exUpload() {
log.info("/exUpload..");
}
// 자동 수집이 가능
@RequestMapping(value = "/exUploadPost", method = RequestMethod.POST)
public void exUploadPost(ArrayList<MultipartFile> files) throws Exception{
log.info("/exUploadPost...............");
for (int i = 0; i < files.size(); i++) {
log.info("--------------------------------");
log.info(files.get(i).getOriginalFilename());
log.info(files.get(i).getSize());
}
for (MultipartFile multipartFile : files) {
log.info("*********************************");
log.info(multipartFile.getOriginalFilename());
log.info(multipartFile.getSize());
}
// 람다 표기법
//
files.forEach(file -> {
log.info("+++++++++++++++++++++++++++++++++");
log.info(file.getOriginalFilename());
log.info(file.getSize());
});
}
servlet-context.xml 에 추가
<!-- 등록 파일 용량 제한 -->
<beans:bean id="multipartResolver" class="org.springframework.web.multipart.commons.CommonsMultipartResolver">
<beans:property name="maxUploadSize" value="10485760"/>
</beans:bean>
http://localhost:9000/sample/exFileUpload
접속 후 첨부파일 전체 등록하고 파일등록해서 전송하기
9. 에러발생시키기
pakage 추가 > CommonExceptionActive 클래스 파일 추가
package com.smart.hrd.exception;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.ui.Model;
import org.springframework.web.bind.annotation.ControllerAdvice;
import org.springframework.web.bind.annotation.ExceptionHandler;
@ControllerAdvice
public class CommonExceptionActive {
private static final Logger log = LoggerFactory.getLogger(CommonExceptionActive.class);
@ExceptionHandler(Exception.class)
public String except(Exception ex, Model model) {
log.error("Exceiption...........{}", ex);
model.addAttribute("exception", ex);
log.info("model................{}", model);
return "error_page";
}
}
views 폴더 경로에 error_page.jsp 생성
<%@ page language="java" contentType="text/html; charset=UTF-8"
pageEncoding="UTF-8"%>
<%@ taglib uri="http://java.sun.com/jsp/jstl/core" prefix="c" %>
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>error_exception.jsp</title>
</head>
<body>
<h4><c:out value="${exception.getMessage() }"></c:out></h4>
<ul>
<!-- exception.getStackTrace() 는 자바에서 예외를 처리할 때 사용하는 메서드 중 하나 -->
<c:forEach items="${exception.getStackTrace() }" var="stack">
<li><c:out value="${stack }"></c:out></li>
</c:forEach>
</ul>
</body>
</html>
import pandas as pd
import matplotlib.pyplot as plt
2. 파일 불러오기
# 파일 불러오기 - bmi_500.csv
bmi = pd.read_csv('bmi_500.csv', index_col = 'Label') # Label 컬럼을 인덱스로 사용하기
bmi
판다스는 넘파이를 기반으로 한다. 시리즈는 ndarray
3. 파일 최상위 5개 확인
bmi.head() # 최상위 데이터 5개만 확인하기
4. 파일 정보 보기
# 대략적인 정보확인 가능
# 전체 row수, 컬럼별 정보 확인, 결측치 여부
bmi.info()
# 결측치가 없다!
Index : 데이터 총 개수, 행의 총 개수
Data columns : 컬럼 총 개수
Non-Null : 결측치가 없다
5. 기술통계 보기
# 기술통계 확인 : 의미가 있는 통계
bmi.describe()
count : 데이터 개수
min : 최소 값
max : 최대 값
25%~75% : 사분위수 뜻함
std: 표준편차
mean : 평균 값
대부분의 데이터가 아래쪽에 몰려있다.
6. 중복없이 인덱스 이름 보기
bmi.index.unique() # 중복없이 본다
# 총 6개가확인됨
7. Label 이 Normal 인 사람의 데이터만 가져오기
bmi.loc['Normal'] #loc 원하는 컬럼만 가져오기/ loc = 문자 인덱스 선택, iloc = 숫자 index 선택
8. 라벨이 Normal 인 사람들의 키 (Height) 컬럼 가져오기
# 인덱스가 Normal 인사람의 키만 가져오기
bmi.loc['Normal','Height']
# 두번째 방법 bmi.loc['Normal']['Height']
9. 산점도 그려보기
함수 호출생성
# 산점도
# 함수 생성
def myScatter (label, color) : # 점을 흩뿌리다
tmp = bmi.loc[label] # 라벨에 매개변수의 라벨인 데이터만 담기
plt.scatter(tmp['Weight'], # x 값
tmp['Height'], # y 값
c = color, # 컬러는 매개변수의 컬럼
label = label)
함수 호출
# 산점도 그리는 함수 호출
plt.figure(figsize=(5,5))
myScatter('Extreme Obesity', 'red')
myScatter('Weak', 'black')
myScatter('Obesity', 'purple')
myScatter('Normal', 'blue')
myScatter('Overweight', 'green')
myScatter('Extremely Weak', 'pink')
plt.xlabel('Weight')
plt.ylabel('Height')
plt.legend() # legend() =범례 : 기호, 색상, 라인 등이 어떤 데이터를 나타내는지 설명하는 정보
plt.show()
클래스 별로 분류가 잘되어 보여서 이상태로 모델링 해도 될 듯싶다는걸 알수있다
10. 모델링 시작
head로 맨위 데이터 한개 가져오기
bmi.head(1)
# 인덱스를 리셋(컬럼으로)
bmi.reset_index(inplace=True) # inplace 시킨 걸 bmi에 바로 적용시키겠다
# 안그러면 재할당 해줘야 한다 bmi = bmi.reset_index(inplace=True) 이렇게
bmi.head(2)
데이터 나누기
# 1. 문제와 답으로 분리
X = bmi[['Height','Weight']] # 문제
y = bmi['Label'] # 답
11. 학습 데이터와 테스트 데이터로 나누기
# 2. train(훈련셋)과 test(평가셋)분리
# 훈련, 평가는 7:3으로 나누어준다
# iloc 는 인덱싱을 도와주는 함수 (행과열을 할 때 도와줌)
X_train = X.iloc[:350]
y_train = y.iloc[:350]
X_test = X.iloc[350:]
y_test = y.iloc[350:]
VO와 DTO는 둘 다 객체지향 프로그래밍에서 사용되는 용어로, 데이터 전달 및 관리를 위한 클래스를 구현할 때 사용
VO는 값을 읽고 반환하는 데 사용되는 단순한 객체이며, DTO는 서로 다른 계층 간에 데이터를 전달하기 위한 객체입니다. VO는 불변성을 가지고 있고, DTO는 가변성을 가질 수 있습니다
화면쪽과 가까우면 dto, 모델과 가까우면 vo
1. 패키지 생성
컬럼에 스네이크 표기법을 쓴다.
우리는 카멜표기법을 쓴다.
JPA(Java Persistence API)는 자바 진영에서 ORM(Object-Relational Mapping) 기술을 표준화한 API입니다. JPA는 데이터베이스와 객체 간의 매핑 작업을 편리하게 처리할 수 있도록 해주며, 개발자는 SQL 쿼리를 직접 작성하지 않아도 객체를 통해 데이터를 조작할 수 있습니다.
2. 클래스 생성 SampleDTO
@Data 어노테이션은 Getter Setter RequiredArgsConstructor ToString EqualsAndHashCode lombok.Value 을 만들어준다
package com.smart.hrd;
import java.util.ArrayList;
import java.util.Arrays;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestMethod;
import org.springframework.web.bind.annotation.RequestParam;
import com.smart.hrd.domain.SampleDTO;
import lombok.extern.log4j.Log4j;
@Controller // 컨트롤러가 찾아올 수 있게
@RequestMapping("/sample") //
// @RequestMapping("/sample/*") // 또다른 방법
@Log4j
public class SampleController {
// 뒤에 경로를 안써주면 /sample 만 적어주면 실행됨
//@RequestMapping("")
@GetMapping("/basic")
public void basic() {
log.info("basic1................................");
}
// @RequestMapping(value="/basic", method = {RequestMethod.GET,RequestMethod.POST}) // 잘 안씀
@RequestMapping(value="/basic1", method = {RequestMethod.GET,RequestMethod.POST})
public void basicGet() {
log.info("basic1...........");
}
@RequestMapping(value="/basic1", method = RequestMethod.POST)
public void basicPost() {
log.info("basic3...........");
}
@GetMapping("/ex01") // url 주소로 메소드 명을 만들면 편하다
public String ex01(SampleDTO sDto) { // 메소드의 구성요소 / 접근제한자, 반환자료형, 메소드명, 매개변수()
log.info(sDto); // 타입도 자동 변환해준다. (쿼리스트링은 문자열로 내려오는데..)
return "ex01"; // return 값으로 jsp 파일명을 넣어준다
}
@GetMapping("/ex02List")
public String ex02List(@RequestParam("ids") ArrayList<String> ids) { // @RequestParam() 배열 형식의 데이터 넘길때
log.info("ids ==> "+ids);
return "ex02List";
}
@GetMapping("/ex02Array")
public String ex02Array(@RequestParam("ids") String[] ids) {
log.info("ids ==> "+Arrays.toString(ids));
return "ex02Array";
}
}
ArrayList와 HashMap
ArrayList와 HashMap은 모두 자바에서 제공하는 컬렉션 프레임워크의 일부분입니다. ArrayList는 크기를 조정할 수 있는 배열이며, 원소들은 인덱스를 이용하여 접근할 수 있습니다. 즉, 순서가 있고 중복된 값이 허용됩니다. HashMap은 key-value 쌍으로 이루어진 데이터를 저장하는 자료구조로, 원소들은 key를 이용하여 접근합니다. 즉, 순서가 없고 key는 중복될 수 없지만, value는 중복될 수 있습니다. 따라서 ArrayList는 원소들을 인덱스로 접근하고, HashMap은 key를 이용하여 값을 찾습니다. ArrayList의 장점은 인덱스를 이용하여 빠르게 원소에 접근할 수 있으며, 순서가 있어서 정렬이 용이합니다. HashMap의 장점은 key를 이용하여 빠르게 값을 찾을 수 있으며, 검색과 삭제의 성능이 좋습니다. ArrayList는 순서가 있기 때문에, 데이터의 삽입과 삭제가 중간에 일어날 경우 성능이 떨어질 수 있습니다. 그러나 HashMap은 순서가 없기 때문에, 데이터의 순서를 유지해야 할 때는 사용하기 어렵습니다. 따라서 ArrayList와 HashMap은 서로 다른 용도로 사용되며, 어떤 상황에서 사용할지는 데이터의 특성과 사용할 목적에 따라 결정해야 합니다.
그래서 @InitBinder 처리를 해준다 다른 방법으로는 dto 에서 @DateTimeFormat 어노테이션 추가해주기
@InitBinder
@DateTimeFormat
TodoDTO
package com.smart.hrd.domain;
import java.util.Date;
import org.springframework.format.annotation.DateTimeFormat;
import lombok.Data;
@Data
public class TodoDTO {
private String title;
@DateTimeFormat(pattern="yyyy/MM/dd")
private Date dueDate;
}
SampleController
// dto에서 @DateTimeFormat 방식으로 사용해서 주석처리해놓음
// @InitBinder
// public void initBinder(WebDataBinder binder) {
// // data 포맷 방식 - simple 포맷방식,
// SimpleDateFormat dateFormat = new SimpleDateFormat("yyyy-mm-dd");
//
// binder.registerCustomEditor(java.util.Date.class, new CustomDateEditor(dateFormat, false));
// }
// 날짜 데이터 타입
@GetMapping("/ex03")
public String ex03(TodoDTO todo) {
// 에러가 나는게 맞다. 날짜 타입은 자동 변환 안됨
// 그래서 initBinder를 추가해줌 혹은 dto 에 @DateTimeFormat 추가
log.info("todo ==========>" + todo);
return "ex03";
}
7. SampleController 에 함수 추가 , views 폴더에 sample 폴더 생성 후 sample.jsp 생성
// Model 은 ui와 관련이 있다.
@GetMapping("/sampleModel")
public String sampleModel(Model model) {
// 생성과 동시에 초기화
SampleDTO sampleDTO = new SampleDTO("홍길동",18);
// sampleDTO.setAge(0); : 직접 초기화방식
log.info("sampleModel ======>" + sampleDTO );
// addAttribute() 사용 형태
// 1. addAttribute("이름", 객체) : 객체에 특별한 이름을 부여해 뷰에서 이름값을 이용하여 객체처리
// 2. addAttribute(객체) : 이름을 지정하지 않는 경우에는 자동으로 저장되는 객체의 클래스명 앞 글자를 소문자로 처리한 클래스 명을 이름으로 간주함.
// 이름 변경해서 쓰는 방법
//model.addAttribute("aaaa",sampleDTO);
// 변수명 그대로 이름쓰는방법
model.addAttribute(sampleDTO);
return "/sample/sample";
}
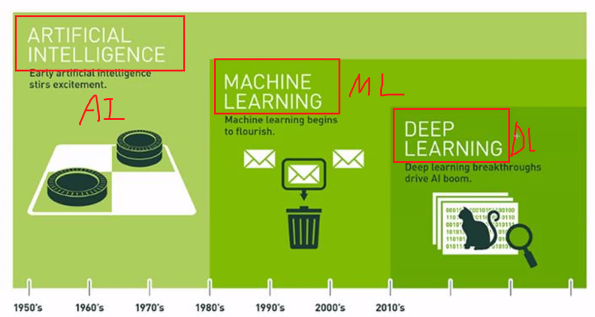
머신러닝 (Machine Learning)이란? . 기계학습 - 컴퓨터를 학습시키는 것 인공지능(Artificial Intelligence)의 한 분야 프로그래밍 된 컴퓨터 컴퓨터가 데이터를 분석하고 학습하여 스스로 패턴을 찾고 예측하는 능력을 갖추도록 하는 기술 . 크게 3가지로 분류 됨 지도학습(Supervised Learning) 비지도학습(Unsupervised Learning) 강화학습(Reinforcement Learning) . 바둑의 경우의 수는 첫 수부터 모든 수까지 약 2 x 10^170 개
머신러닝의 출현
머신러닝의 아버지 엘런 튜링
엘런 튜링의
" 1950년도에 기계가 인간과 같은 사고를 할 수 있는가? "
가 화두가 되었다.
머신러닝의 발전
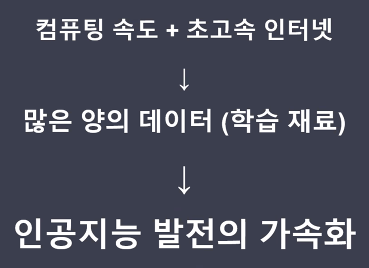
컴퓨터가 공부할 자료는 데이터이다.
산업혁명
18세기 영국에서부터 시작되었음
획기적으로 바뀌게 되는 계기
산업혁명의 흐름
1차 기계
2차 전기
3차 컴퓨터
4차 AI, IoT, BigData
인공지능 (Artificial Intelligence)
머신러닝
사람을 흉내내는 모든 분야
정확한 규칙을 세워서 처리하는 일
세상에는 모든 일에 규칙을 세울 수가 없다. -> 머신러닝 탄생
사람을 흉내내는 걸 학습시킨다.
데이터를 기반으로 학습을 시켜서 예측하게 만드는 기법
인공지능의 한 분야로 컴퓨터가 학습 할 수 있도록 하는 알고리즘과 기술을 개발하는 분야
학습을 통해
데이터를 이용하여 특성과 패턴을 학습하고 그 결과를 바탕으로 미지의 데이터에
통계학, 데이터마이닝, 컴퓨터 과학이 어우러진 분야
데이터 마이닝 : 대규모 데이터에서 유용한 정보를 추출하는 프로세스
자연어 처리
딥러닝
매번 똑같지 않게 생겼지만 같은 사람을 구분하고 분류하는것
고양이인지 개인지 구분하는 것
추상적인 걸 학습시켜 사람처럼 판별이 가능하게 하는 것
Rule-based expert system
단점
스팸 메일 필터가 안된다..
매번 같은 표정, 옷 일 수가 없기에 얼굴 인식 시스템 개발 불가
많은 상황에 대한 규칙들을 모두 만들어 낼 수 없다.
머신러닝
- 머신러닝이란 학습을 통해 새로운 데이터를 예측하거나 분류하는 것
데이터를 이용하여 특성과 패턴을 학습 -> 미래 결과를 예측 (판단, 추론)
의료 인공지능 분야 사례
영상 의료/병리 데이터의 분석 및 판독 (Deep Learning) - 영상의학과 전문의
산업 인공지능 분야 사례
신제품 마케팅 - 인공지능 트렌드 분석 시스템 '엘시아(LCIA)'
예술 인공지능 분야 사례
머신러닝 종류
지도학습 (Supervised Learning)
이게 문제이고, 이게 답이야 라고 알려줌
데이터에 대한 라벨 (명시적인 답) 이 주어진 상태에서 컴퓨터를 학습시키는 방법
규칙을 찾아감
분류와 회귀로 나뉘어진다. - 분류와 회귀로 나눠지는 것에 문제는 중요하지 않다. 답이 중요하다.
분류 (Classification)
미리 정의된 여러 클래스 레이블 중 하나를 예측
속성(Attribute)값을 입력, 클래스 값을 출력하는 모델 -> 모델에 문제를 입력하고 답을 출력 시키는 모델
붓꽃(iris)의 세 품종 중 하나로 분류, 암 분류 등.
예측값이 다르면 타격이 크다
이진분류, 다중 분류 등이 있다
이진분류 (Binary Classification) : 둘 중 하나
다중분류 (Multi-class Classification) : 여러 개 중 하나
회귀 (Regression)
연속적인 숫자를 예측
속성 값을 입력, 연속적인 실수 값을 출력하는 모델
어떤 사람의 교육 수준, 나이, 주거지를 바탕으로 연간 소득 예측.
예측 값의 미묘한 차이가 크게 중요하지 않다. -> 조금 달라도 별 차이가 없다.
지도, 비지도, 강화중에서 가장 중점이 된다.
예시
스팸메일 분류 - 분류
집 가격 예측 - 회귀 (연속적인 수치를 예측)
class = lable = 답
feature = attribute = column = 문제
비지도학습 (Unsupervised Learning)
지도학습이 아니다.
데이터에 대한 정답이 없는 상태에서 컴퓨터를 학습
학습시키려는데 문제는 있으나 답이 명시적이지 않다.
데이터의 숨겨진 특징, 구조, 패턴을 파악하는데 사용
데이터를 비슷한 특성끼리 묶는 클러스터링 (Clustering)과 차원 축소 (Dimensionality Reduction)등이 있다.
클러스터링 : 데이터 내에서 유사한 패턴이나 구조를 찾아 그룹화하는 것을 목적
차원 축소 : 고차원의 데이터를 저차원으로 축소시키는 기법
강화학습(Reinforcement Learning)
지도학습과 비슷하지만 완전한 답(Label)을 제공하지 않는 특징이 있음
특정한 환경(Environment) 내에서 행동(Action)을 하고, 그에 대한 보상(Reward)을 받아 보상을 최대화하는 방향으로 학습을 진행하는 것
기계는 더 많은 보상을 얻을 수 있는 방향으로 행동을 학습
주로 게임이나 로봇을 학습시키는데 많이 사용
머신러닝이 유용한 분야
기존 솔루션으로는 수동 조정과 규칙이 필요한 문제
전통적인 방식으로는 전혀 해결 방법이 없는복잡한 문제
새로운 데이터에 적응해야하는 유동적인 환경
대량의 데이터에서 통찰을 얻어야 하는 문제
머신러닝 과정
문제 정의 (Problem Identification)
비즈니스 목적 정의
모델을 어떻게 사용해 이익을 얻을까?
현재 솔루션의 구성 파악
지도 vs 비니도 vs 강화
분류 vs 회귀
데이터 수집 (Data Collect)
File (csv, xml, json)
Database
Web Crawler (뉴스, sns, 블로그)
IoT 센서를 통한 수집
Survey
데이터 전처리 (Data Preprocession)
결측치, 이상치 처리
특성공학 (Feature Engineering)
단위변환 (Scaling)
새로운 속성 추출 (Transform)
범주형 -> 수치형 (Encoding)
수치형 -> 범주형 (Binning)
탐색적 데이터 분석 (EDA, Exploratory Data Analysis) - 시각화 그래프
기술통계 (의미가 있는 값), 변수간 상관 관계
시각화
pandas
matplotlib
seaborn
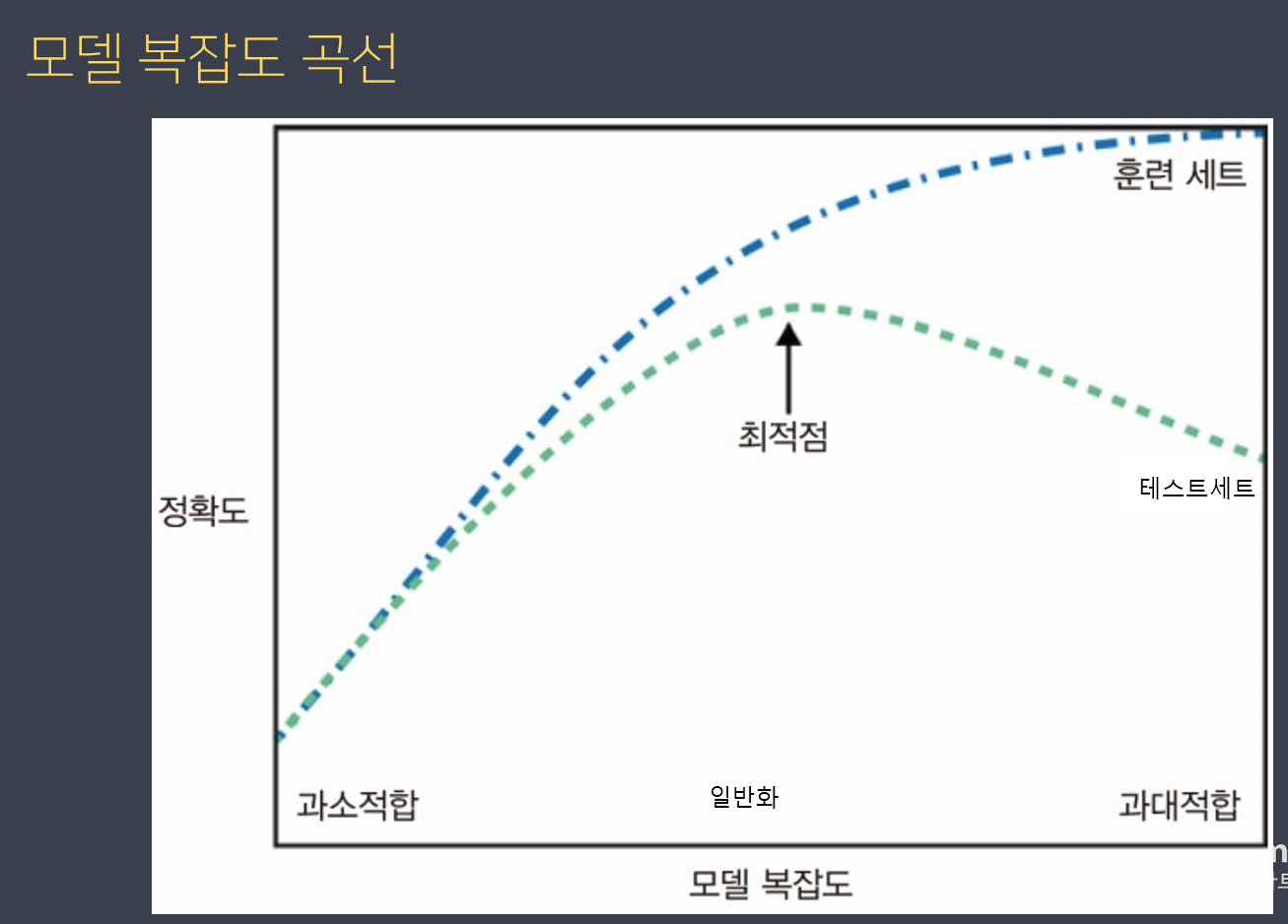
Feature Selection (사용할 특성 선택) - 학습이 잘될 수 있는 특성 선택
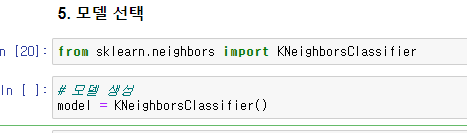
모델 선택, Hyper Parameter 조정
Hyper Parameter : 모델의 성능을 개선하기 위해 사람이 직접 넣는 parameter
목적에 맞는 적절한 모델 선택
KNN, SVM, Linear Regression, Ridge, Lasso, Decision Tree, Random forest, CNN, RNN ...
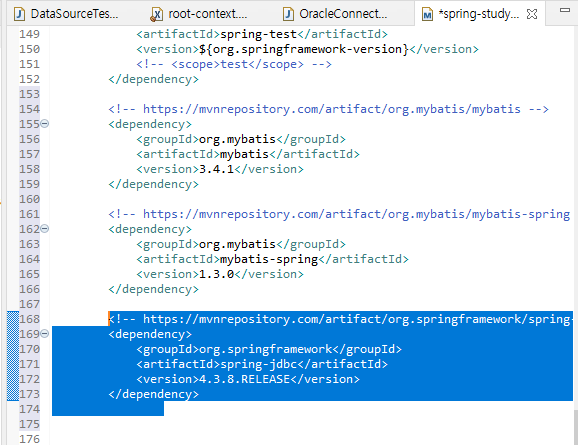
9. root-context.xml > sqlSessionFactory bean 에 property 추가
<property name="configLocation" value="classpath:/mybatis-config.xml"></property> <!-- SqlSessionFactoryBean.class 에 멤버필드에 잡혀있는 이름으로 해준다 -->
10. src.test.java 패키지 > MyBatisTest JUnit 생성
package com.smart.hrd;
import static org.junit.Assert.*;
import org.apache.ibatis.session.SqlSession;
import org.apache.ibatis.session.SqlSessionFactory;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.test.context.ContextConfiguration;
import org.springframework.test.context.junit4.SpringJUnit4ClassRunner;
import lombok.extern.log4j.Log4j;
@RunWith(SpringJUnit4ClassRunner.class)
@ContextConfiguration("file:src/main/webapp/WEB-INF/spring/root-context.xml")
@Log4j
public class MyBatisTest {
@Autowired // 스프링 관리하는 빈(bean) 내에서 의존성(dependency)을 자동으로 주입(injection)해주는 기능
private SqlSessionFactory sqlFactory;
@Test
public void test() {
log.info(sqlFactory);
}
@Test // 테스트라는 어노테이션이 붙어있어야 호출된다.
public void testSession() {
try (SqlSession session = sqlFactory.openSession()) {
// io , database 객체, 빨간줄이 뜬다. 그러면 컴파일이 안되고 클래스 파일이 생성이 안되고, 실행이 안된다.
// 예외처리 종류 3가지 try catch, throws, throw
log.info(session);
} catch (Exception e) {
e.printStackTrace();
}
}
}
Run As 실행시 초록 불 떠야함
Mybatis 쓰는 방식이 3가지가 있다.
1. XML 기반 Mapper 사용 방식
2. 어노테이션 기반 Mapper 사용 방식
3. Mix 방식
3. Mapper interface 방식 - 댓글달기 할 때 수업할 예정
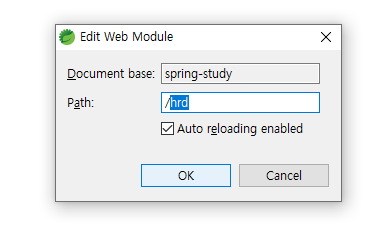
11. path 숨기기 > 서버 더블클릭 > Modules 클릭 > Edit...클릭
톰캣 서버 더블클릭
Moduls 클릭
Edit... 클릭
hrd 지우고 OK 클릭
Path 지워진 것 확인
톰캣 서버 실행버튼 클릭해주고
http://localhost:9000/
경로 들어가면 들어가면 잘 나옴
##
기존 -> /hrd/ 필요없어짐
경로숨기기
##
12. SampleController 클래스 생성
SampleController
package com.smart.hrd;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.RequestMapping;
import lombok.extern.log4j.Log4j;
@Controller // 컨트롤러가 찾아올 수 있게
@RequestMapping("/sample") //
// 또다른 방법 @RequestMapping("/sample/*")
@Log4j
public class SampleController {
@RequestMapping("") // 뒤에 경로를 안써주면 /sample 만 적어주면 실행됨
public void basic() {
log.info("basic1................................");
}
}